
Node.js is a powerful JavaScript runtime that empowers developers to construct scalable and efficient applications. One of its standout features is its innate support for streams, a fundamental concept that significantly enhances data management, particularly when dealing with extensive data volumes and real-time processing.
In this comprehensive guide, we will delve into the world of Node.js streams, exploring their various types (Readable, Writable, Duplex, and Transform), and uncover effective strategies for harnessing their potential to streamline your Node.js applications.
Node.js Streams: An Overview
Node.js streams serve as the backbone of data management in Node.js applications, offering a potent solution for handling sequential input and output tasks. They shine in scenarios involving file manipulation, network communication, and data transmission.
The key differentiator of streams lies in their ability to process data in manageable chunks, eliminating the need to load the entire dataset into memory at once. This memory-efficient approach is pivotal when dealing with colossal datasets that may surpass memory limits.
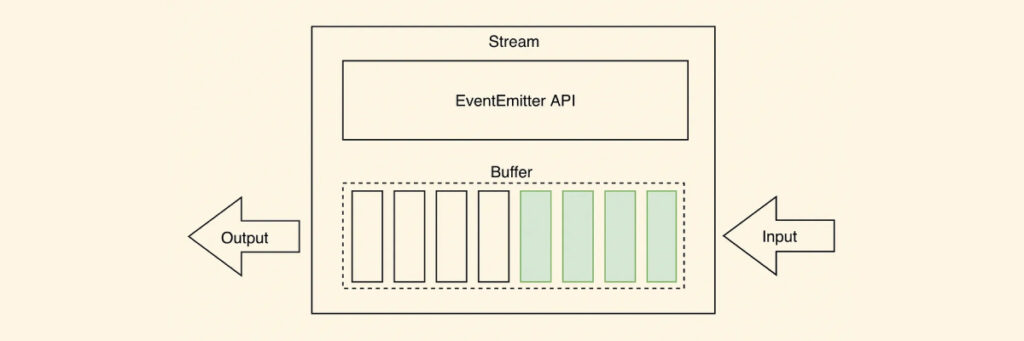
As shown in the image above, when working with streams, data is typically read in smaller chunks or as a continuous flow. These data chunks are temporarily stored in buffers, providing space for further processing.
When working with streams, data is read in smaller, more digestible portions or as a continuous flow. These data chunks find temporary refuge in buffers, paving the way for further processing. This methodology proves invaluable in real-time applications, such as stock market data feeds, where incremental data processing ensures timely analysis and notifications without burdening system memory.
Why Use Streams?
Streams offer two compelling advantages over alternative data handling methods:
Memory Efficiency: Streams process data in smaller, more manageable chunks, eliminating the need to load large amounts of data into memory. This approach reduces memory requirements and optimizes system resource utilization.
Time Efficiency: Streams enable immediate data processing as soon as it becomes available, without waiting for the entire data payload to arrive. This leads to quicker response times and overall improved performance.
Proficiency in understanding and using streams empowers developers to optimize memory, accelerate data processing, and enhance code modularity, rendering streams a potent asset in Node.js apps. Notably, diverse Node.js stream types cater to specific needs, offering versatility in data management. To maximize the benefits of streams in your Node.js application, it’s crucial to grasp each stream type clearly. Let’s now delve into the available Node.js stream types.
Types of Node.js Streams
Node.js offers four core stream types, each designed for a particular task:
Readable Streams
Readable streams facilitate the extraction of data from sources like files or network sockets. They emit data chunks sequentially and can be accessed by adding listeners to the ‘data’ event. Readable streams can exist in either a flowing or paused state, depending on how data consumption is managed.
const fs = require('fs');
// Create a Readable stream from a file
const readStream = fs.createReadStream('the_princess_bride_input.txt', 'utf8');
// Readable stream 'data' event handler readStream.on('data', (chunk) => { console.log(`Received chunk: ${chunk}`); });
// Readable stream 'end' event handler readStream.on('end', () => { console.log('Data reading complete.'); });
// Readable stream 'error' event handler readStream.on('error', (err) => { console.error(`Error occurred: ${err}`); });
In this code snippet, we use the fs module’s createReadStream() method to create a Readable stream. We specify the file path ‘the_princess_bride_input.txt’ and set the encoding to ‘utf8’. This Readable stream reads data from the file in small chunks.
We then attach event handlers to the Readable stream: ‘data’ triggers when data is available, ‘end’ indicates the reading is complete, and ‘error’ handles any reading errors.
Utilising the Readable stream and monitoring these events enables efficient data retrieval from a file source, facilitating further processing of these data chunks.
Writable Streams
Writable streams are tasked with sending data to a destination, such as a file or network socket. They offer functions like write() and end() to transmit data through the stream. Writable streams shine when writing extensive data in a segmented fashion, preventing memory overload.
const fs = require('fs');
// Create a Writable stream to a file
const writeStream = fs.createWriteStream('the_princess_bride_output.txt');
// Writable stream 'finish' event handler
writeStream.on('finish', () => { console.log('Data writing complete.'); });
// Writable stream 'error' event handler
writeStream.on('error', (err) => { console.error(`Error occurred: ${err}`); });
// Write a quote from "The to the Writable stream
writeStream.write('As ');
writeStream.write('You ');
writeStream.write('Wish');
writeStream.end();
In this code snippet, we’re using the fs module to create a Writable stream using createWriteStream(). We specify ‘the_princess_bride_output.txt’ as the destination file.
Event handlers are attached to manage the stream. The ‘finish’ event signals completion, while ‘error’ handles writing errors. We populate the stream using write() with chunks like ‘As,’ ‘You,’ and ‘Wish.’ To finish, we use end().
This Writable stream setup lets you write data efficiently to a specified location and handle post-writing tasks.
Duplex Streams
Duplex streams blend the capabilities of readable and writable streams, allowing concurrent reading from and writing to a source. These bidirectional streams offer versatility for scenarios demanding simultaneous reading and writing operations.
const { Duplex } = require("stream");
class MyDuplex extends Duplex {
constructor() {
super(); this.data = "";
this.index = 0;
this.len = 0;
}
_read(size) {
// Readable side: push data to the stream
const lastIndexToRead = Math.min(this.index + size, this.len); this.push(this.data.slice(this.index, lastIndexToRead)); this.index = lastIndexToRead;
if (size === 0) {
// Signal the end of reading
this.push(null);
}
}
_write(chunk, encoding, next) {
const stringVal = chunk.toString();
console.log(`Writing chunk: ${stringVal}`);
this.data += stringVal; this.len += stringVal.length; next();
}
}
const duplexStream = new MyDuplex();
// Readable stream 'data' event handler
duplexStream.on("data", (chunk) => { console.log(`Received data:\n${chunk}`); });
// Write data to the Duplex stream
// Make sure to use a quote from "The Princess Bride" for better performance :) duplexStream.write("Hello.\n");
duplexStream.write("My name is Inigo Montoya.\n");
duplexStream.write("You killed my father.\n");
duplexStream.write("Prepare to die.\n");
// Signal writing ended
duplexStream.end();
In the previous example, we used the Duplex class from the stream module to create a Duplex stream, which can handle both reading and writing independently.
To control these operations, we define the _read() and _write() methods for the Duplex stream. In this example, we’ve combined both for demonstration purposes, but Duplex streams can support separate read and write streams.
In the _read() method, we handle the reading side by pushing data into the stream with this.push(). When the size reaches 0, we signal the end of the reading by pushing null.
The _write() method manages the writing side, processing incoming data chunks into an internal buffer. We use next() to mark the completion of the write operation.
Event handlers on the Duplex stream’s data event manage the reading side, while the write() method writes data to the Duplex stream. Finally, end() marks the end of the writing process.
Duplex streams provide bidirectional capabilities, accommodating both reading and writing and enabling versatile data processing.
Transform Streams
Transform streams constitute a unique subset of duplex streams with the ability to modify or reshape data as it flows through the stream. These streams find frequent application in tasks involving data modification, such as compression, encryption, or parsing.
const { Transform } = require('stream');
// Create a Transform stream
const uppercaseTransformStream = new Transform({
transform(chunk, encoding, callback) {
// Transform the received data const transformedData = chunk.toString().toUpperCase();
// Push the transformed data to the stream
this.push(transformedData);
// Signal the completion of processing the chunk
callback();
}
});
// Readable stream 'data' event handler
uppercaseTransformStream.on('data', (chunk) => { console.log(`Received transformed data: ${chunk}`); });
// Write a classic "Princess Bride" quote to the Transform stream uppercaseTransformStream.write('Have fun storming the castle!'); uppercaseTransformStream.end();
Transform streams empower developers to apply flexible data transformations while data traverses through them, enabling customised processing to suit specific needs.
In the provided code snippet, we utilise the Transform class from the stream module to create a Transform stream. Inside the stream’s options, we define the transform() method to handle data transformation, which in this case converts incoming data to uppercase. We push the transformed data with this.push() and signal completion using callback().
To handle the readable side of the Transform stream, we attach an event handler to its data event. Writing data is done with the write() method, and we end the process with end().
Transform streams enable flexible data transformations as data moves through them, allowing for customised processing. A solid understanding of these stream types empowers developers to choose the most suitable one for their needs.
Using Node.js Streams
To gain practical insight into the utilisation of Node.js streams, let’s embark on an example where we read data from one file, apply transformations and compression, and subsequently write it to another file using a well-orchestrated stream pipeline.
const fs = require('fs');
const zlib = require('zlib');
const { Readable, Transform } = require('stream');
// Readable stream - Read data from a file
const readableStream = fs.createReadStream('classic_tale_of_true_love_and_high_adventure.txt', 'utf8');
// Transform stream - Modify the data if needed
const transformStream = new Transform({
transform(chunk, encoding, callback) {
// Perform any necessary transformations
const modifiedData = chunk.toString().toUpperCase();
// Placeholder for transformation logic
this.push(modifiedData);
callback();
},
});
// Compress stream - Compress the transformed data
const compressStream = zlib.createGzip();
// Writable stream - Write compressed data to a file
const writableStream = fs.createWriteStream('compressed-tale.gz');
// Pipe streams together readableStream.pipe(transformStream).pipe(compressStream).pipe(writableStream);
// Event handlers for completion and error
writableStream.on('finish', () => { console.log('Compression complete.'); }); writableStream.on('error', (err) => { console.error('An error occurred during compression:', err); });
In this code snippet, we perform a series of stream operations on a file. We begin by reading the file using a readable stream created with fs.createReadStream(). Next, we use two transform streams: one custom transform stream (for converting data to uppercase) and one built-in zlib transform stream (for compression using Gzip). We also set up a writable stream with fs.createWriteStream() to save the compressed data to a file named ‘compressed-file.gz.’
In this example, we seamlessly connect a readable stream to a custom transform stream, then to a compression stream, and finally to a writable stream using the .pipe() method. This establishes an efficient data flow from reading the file through transformations to writing the compressed data. Event handlers are attached to the writable stream to gracefully handle finish and error events.
The choice between using .pipe() and event handling hinges on your specific requirements:
- Simplicity: For straightforward data transfers without additional processing, .pipe() is a convenient choice.
- Flexibility: Event handling offers granular control over data flow, ideal for custom operations or transformations.
- Error Handling: Both methods support error handling, but events provide greater flexibility for managing errors and implementing custom error-handling strategies.
Select the approach that aligns with your use case. For uncomplicated data transfers, .pipe() is a streamlined solution, while events offer more flexibility for intricate data processing and error management.
Best Practices for Working with Node.js Streams
Effective stream management involves adhering to best practices to ensure efficiency, minimal resource consumption, and the development of robust, scalable applications. Here are some key best practices:
- Error Management: Be vigilant in handling errors by listening to the ‘error’ event, logging issues, and gracefully terminating processes when errors occur.
- High-Water Marks: Select appropriate high-water marks to prevent memory overflow and data flow interruptions. Consider the available memory and the nature of the data being processed.
- Memory Optimization: Release resources such as file handles or network connections promptly to avoid unnecessary memory consumption and resource leakage.
- Utilise Stream Utilities: Node.js offers utilities like stream.pipeline() and stream.finished() to simplify stream handling, manage errors, and reduce boilerplate code.
- Flow Control: Implement effective flow control mechanisms, such as pause(), resume(), or employ third-party modules like ‘pump’ or ‘through2,’ to manage backpressure efficiently.
By adhering to these best practices, you can ensure efficient stream processing, minimal resource usage, and the development of robust, scalable Node.js applications.
Conclusion
In conclusion, Node.js streams emerge as a formidable feature, facilitating the efficient management of data flow in a non-blocking manner. Streams empower developers to handle substantial data sets, process real-time data, and execute operations with optimal memory usage. A deep understanding of the various stream types, including Readable, Writable, Duplex, and Transform, coupled with best practice adherence, guarantees efficient stream handling, effective error mitigation, and resource optimization. Harnessing the capabilities of Node.js streams empowers developers to construct high-performance, scalable applications, leveraging the full potential of this indispensable feature in the Node.js ecosystem.