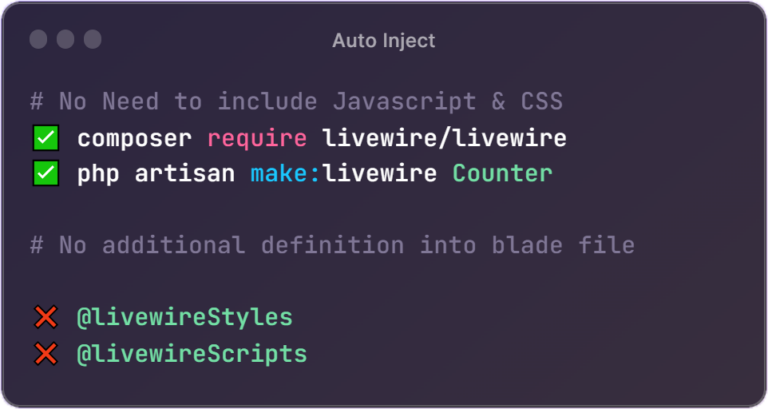
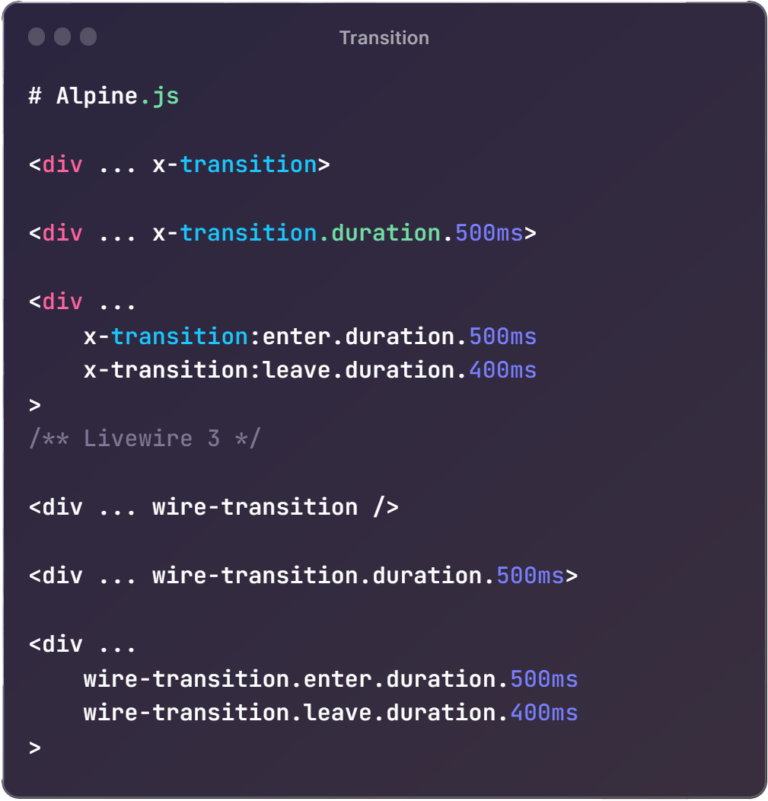
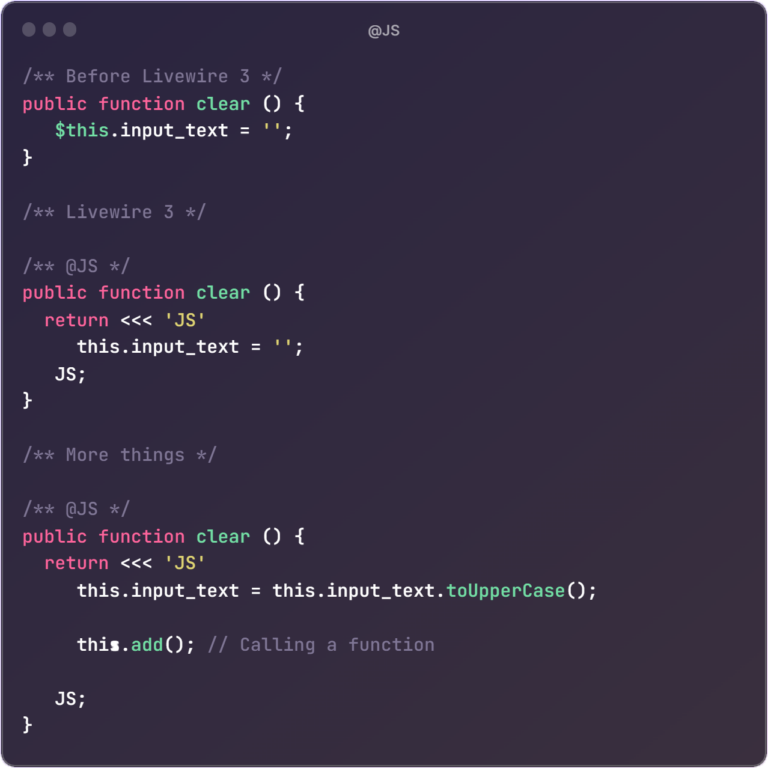
The Laravel community is buzzing with excitement as Taylor Otwell, the brain behind this PHP framework, reveals a sneak peek of Laravel 11 at Laracon US 2023. This release is about to shake up web development. Let’s dive into the changes:
Middleware Directory Disappears
In Laravel 11, the familiar middleware directory in App\Http is gone when you install it. But don’t worry, creating a middleware is still a piece of cake. Just use the artisan command, and it will set everything up for your middleware.
Goodbye HTTP Kernel
Laravel 11 waves goodbye to the Kernel.php file in App\Http, shifting the responsibility for defining new middleware to the app.php file in the bootstrap folder. It’s a significant change signaling Laravel’s adaptability.
// To register custom Middleware
<?php
use Illuminate\Foundation\Application;
use Illuminate\Foundation\Configuration\Exceptions;
use Illuminate\Foundation\Configuration\Middleware;
use App\Http\Middleware\CustomMiddleware;
return Application::configure()
->withProviders()
->withRouting(
web: __DIR__ . '/../routes/web.php',
// api: __DIR__ . '/../routes/apiphp',
commands: __DIR__ . '/../routes/console.php'
)
->withMiddleware( function( Middleware $middleware ) {
//
$middleware->web( append: CustomMiddleware::class );
})
->withExceptions( function( Exceptions $exceptions ){
//
})->create();
Config Files Revamp
The ‘config’ directory gets a makeover in Laravel 11. It now starts empty, with configuration variables finding a new home in the .env file, streamlining configuration management and enhancing security.
Meet ‘config:publish’
A powerful addition to Laravel’s toolkit, ‘config:publish’ simplifies publishing configuration files. For instance, running ‘artisan config:publish database‘ generates a dedicated database configuration file. Precision and organisation at your fingertips.
// To publish all the config files
php artisan config:publish
// Specific config file
php artisan config:publish database
Route Transformation: install:api
Laravel 11 takes a leap in routes by removing the api.php file from the routes directory. To create APIs, the ‘artisan install:api’ command is your new best friend, aligning with Laravel’s commitment to simplicity.
php artisan install:api
Streamlined Broadcasting: install:broadcasting
For apps using broadcast routes or Laravel Echo, Laravel 11 streamlines the process by removing ‘channels.php’ and introducing the ‘artisan install:broadcasting’ command. Real-time communication is easy.
php artisan install:broadcastingFarewell to the Console Kernel
With the removal of the HTTP Kernel, the Console Kernel also bids adieu. Scheduled commands find a new home in the ‘console.php’ file, emphasising Laravel’s adaptability.
Schedule::command('reminder')->hourly()Zero Command Registration
In Laravel 11, there’s no need to register custom artisan commands. They are auto-registered with the Laravel application, prefixed with ‘app:’, ensuring smooth integration and usage.
php artisan make:command TestCommand
// We don't need to register this command
// To use
php artisan app:test-command
Conclusion
The Laravel community, alongside the Laravel Team, is diligently working to implement these groundbreaking changes. As we eagerly await the final release of this remarkable framework, expect more exciting innovations. Laravel is set to maintain its status as the top choice for web application development. Get ready for a new era of web development, marked by efficiency and organisation. Stay tuned for the official release, with more surprises in store.